Down the Rabbit Hole
Johanna SchneiderPlateforme: Wikipedia
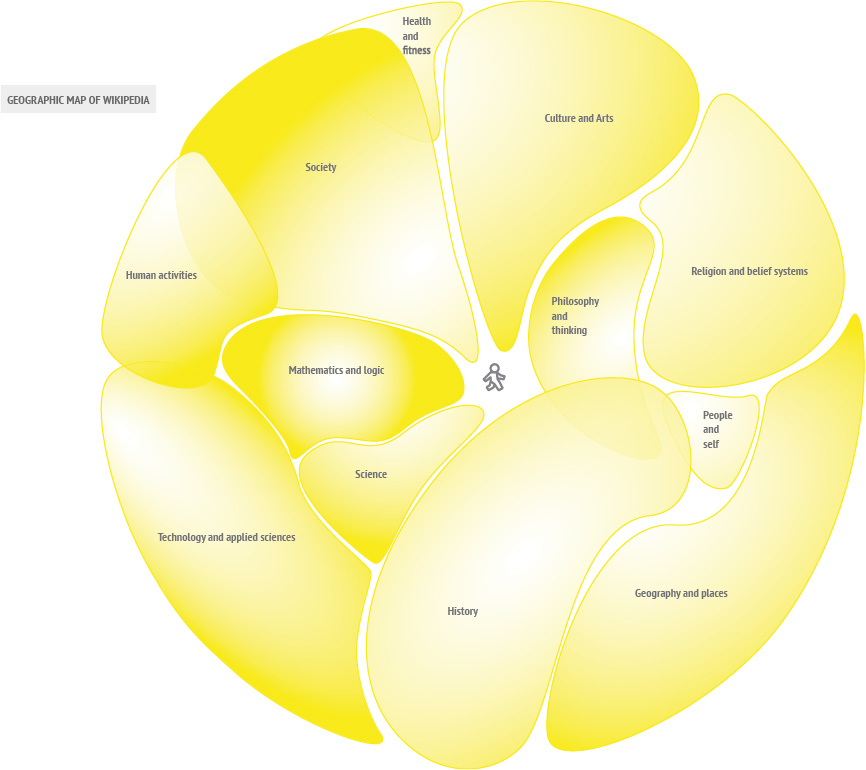
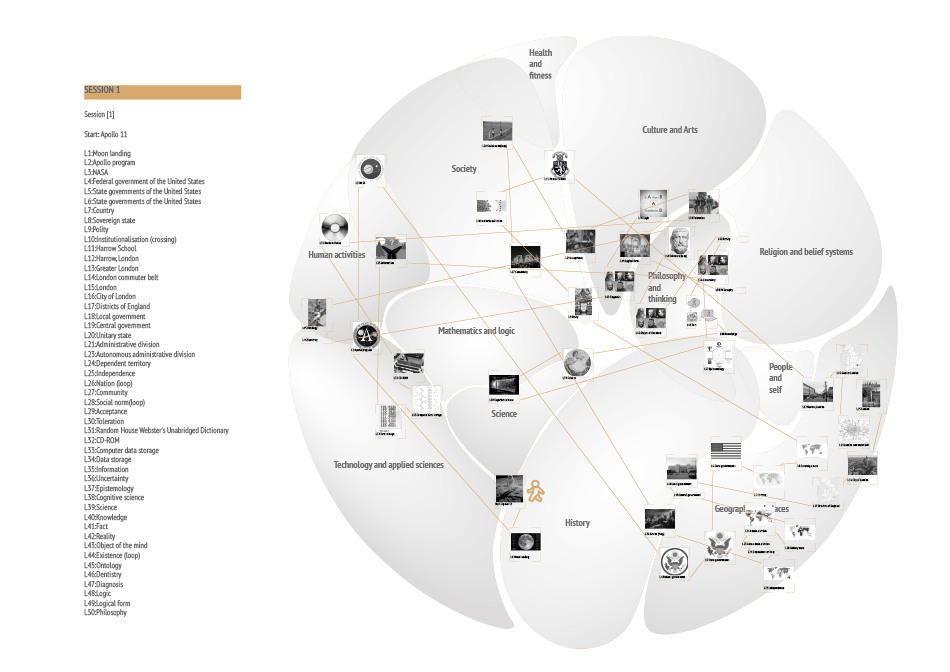
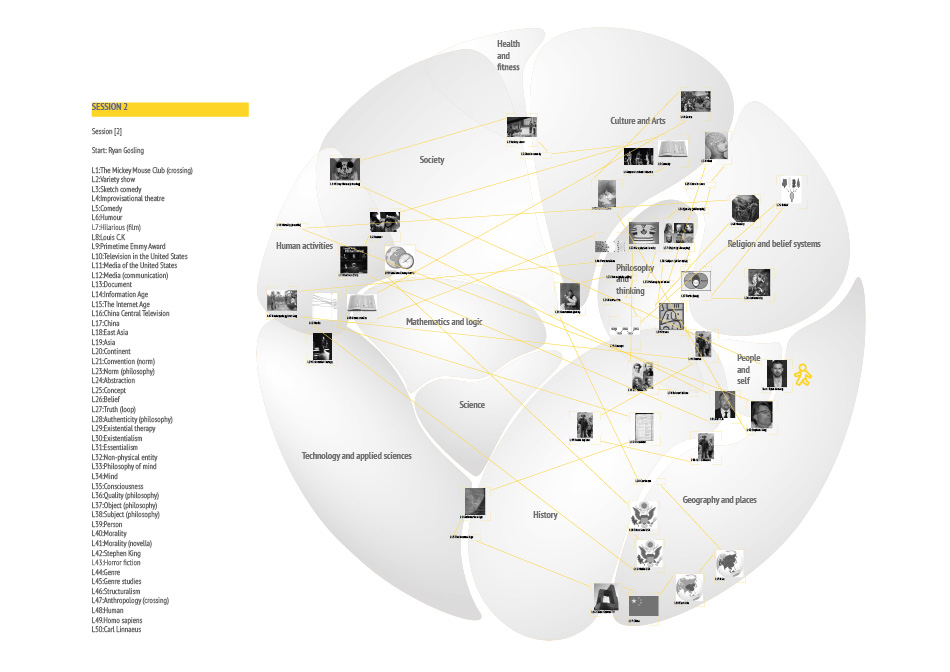
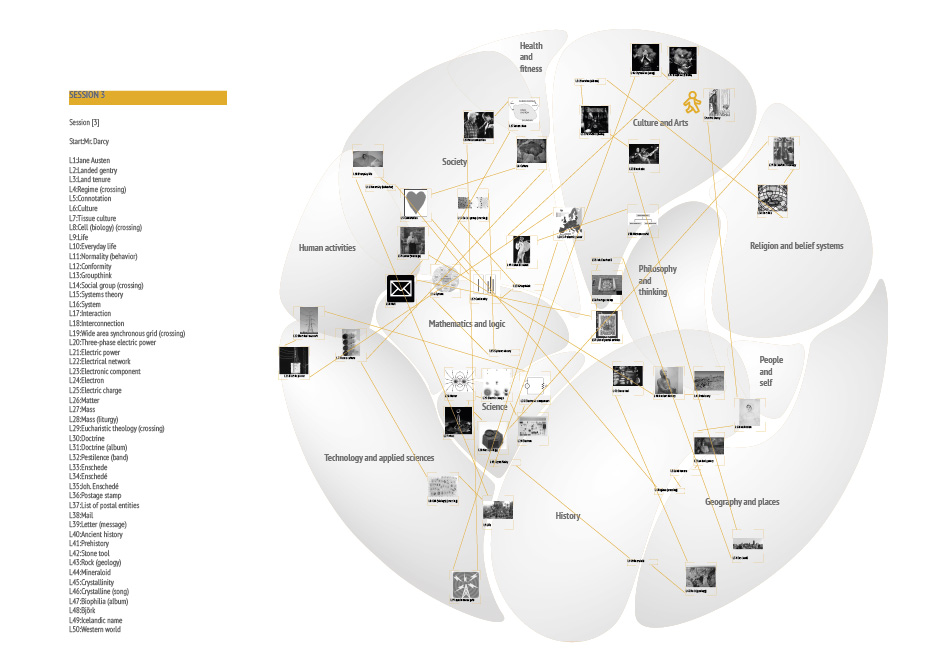
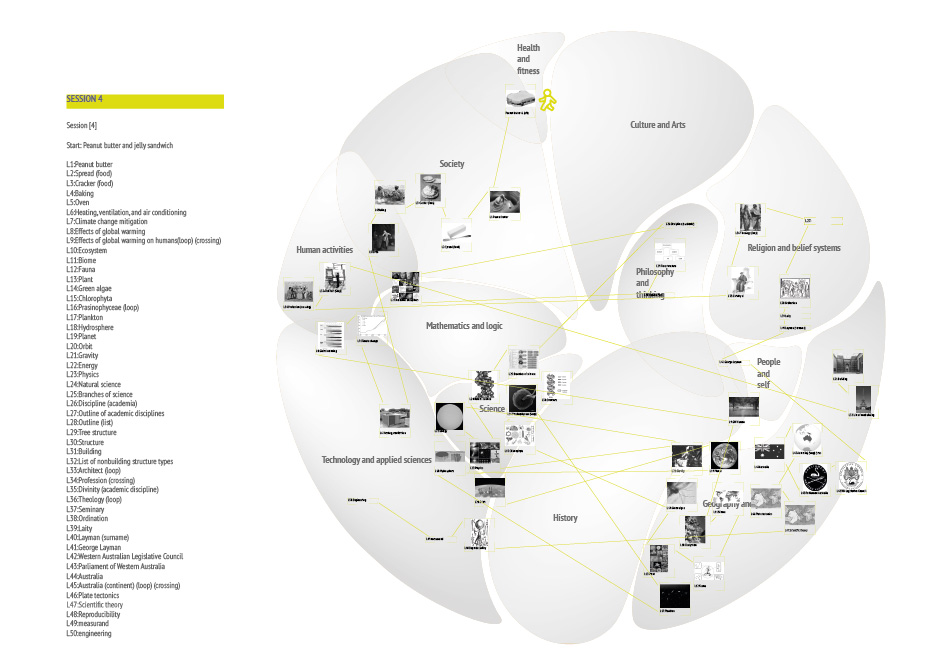
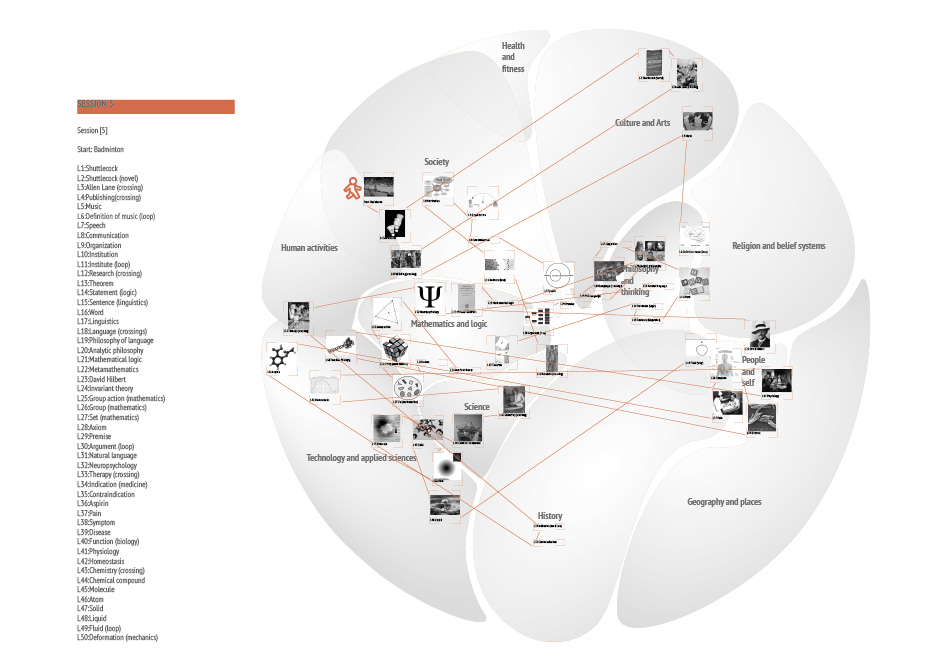
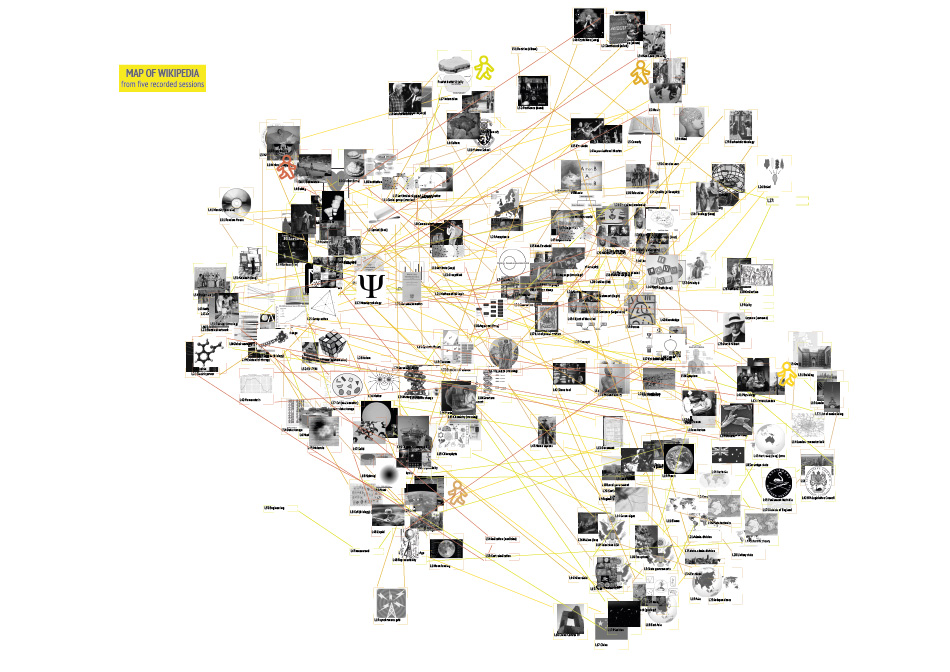
Down the rabbit hole explores the possibilities, challenges and outcomes of getting lost on the internet, specifically the website Wikipedia. Rather than viewing being and getting lost as an unwelcome mistake, it becomes a conscious act to discover the unknown. This practice of deliberate spontaneity and uncertainty goes by the name of“Dérive“ and can be translated to drifting. It isn’t a new concept and has been practiced in a number of different contexts most of them related to Art or Politics. In Guy Debord’s theory of Dérive he explains the rules and advantages of the technique. No matter how one choses to practice it is always essential to leave the usual motivations for doing something behind. Of course this leaves us with a paradox here because we have indeed the motivation to get lost. To free the individual who tries a Dérive on Wikipedia from the problem of choosing the direction and paths to follow, rules have been developed and can be applied. The aim of those rules is to get lost successfully. Successful is defined by a large number of different topics discovered in one Dérive without getting stuck. There are certainly topics wich are easier to leave behind than others, physics being one of them. To document each journey into the unknown fields of Wikipedia, titles and images have to be collected and later registered on the geographic card of Wikipedia. Where in each category people place certain titles might vary so the Dérive is also quit personal. It might be productive to compare the different journeys and associations. What is there to learn about the world and humanity when we do it freed from intensions? Are the hidden truths to be discovered? Or will it simply expand our grasp of the world?
Rulebook:
- A Dérive consists of 50 clicks or „hops“ after the initial randomly selected title.
- Each Dérive has to be recorded and the corresponding data needs to be collected.
- The hopping may take place on the actual Website but when in doubt about the sequence of links or images the URLextractor will be of help.
- Use second link and each article and collect the title and the first image.
- If a loop is starting to form use the third link instead. Do this as well if you notice a path taken on a previous DÉRIVE.
- Ignore links for disambiguation, word explanations and the ones wich explain how to use Wikipedia.
- Loops and crossings have to be marked!

Open as a PDF
Open as a PDF
NEW for YOU: